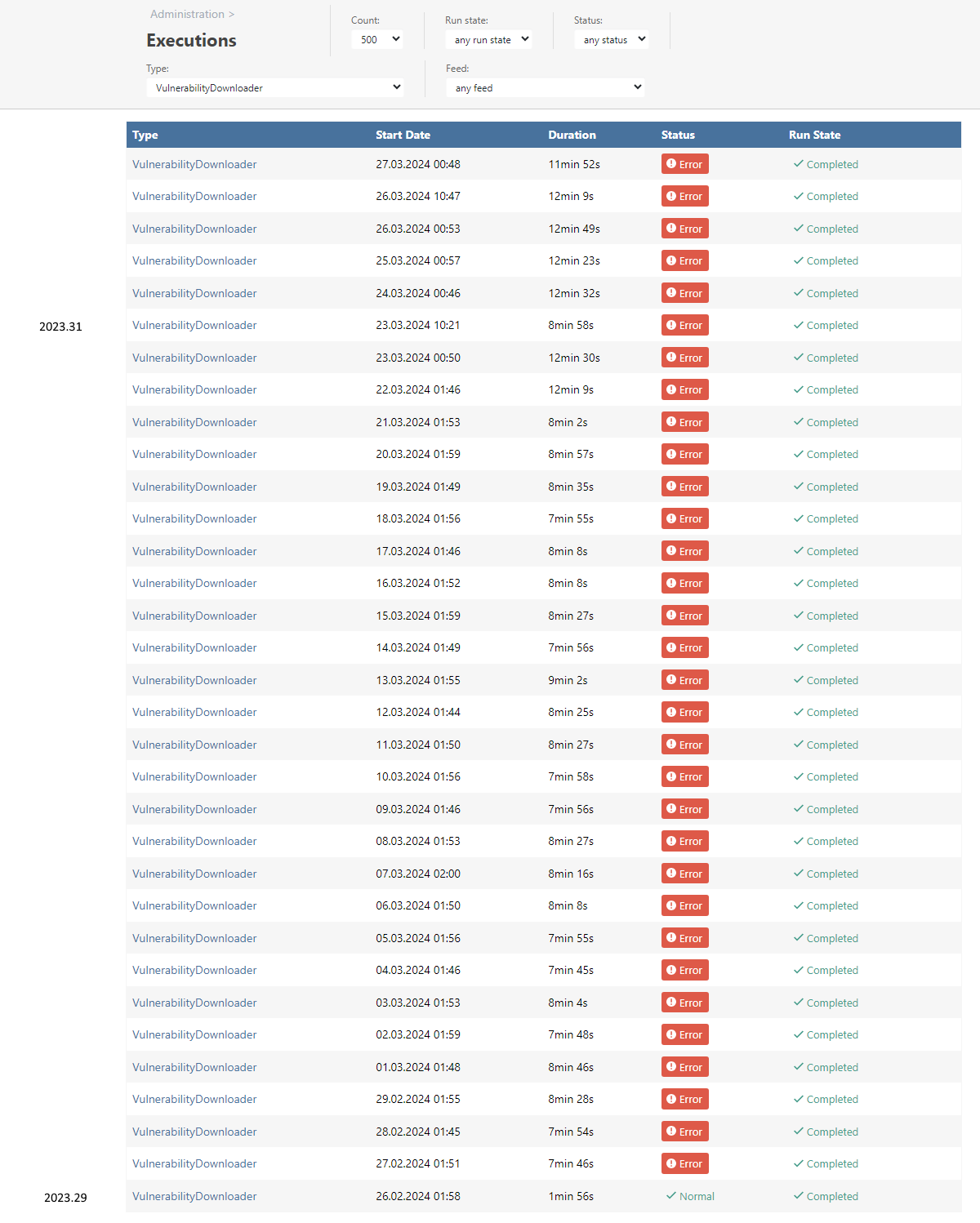
However, the package metadata should already be in ProGet by the time you upload the sbom. When doing package restores from ProGet, the packages will be cached automatically. If that's not happening for you, make sure to clear your nuget package caches.
Not all packages will always be acquired via the remote restore mechanism, as I eluded to here.
They still should be analyzed by SCA and not show up on SCA as "inconclusive".
For example, I just cannot get the System.Security.Cryptography.Primitives populated in the ProGet cache, via regular dotnet restore. The package is always taken from the local dotnet SDK installation folder.
There are also other cases like these framework packages. We have a number of people working via VPN and for performance reasons they are access nuget.org directly, via Microsoft's CDN, which gives them much better performance. Their restore operations will not trigger cache population in ProGet.
Bottom line, there are plenty of scenarios why a package might not be readily available in the ProGet package cache.
Ultimately we designed the SCA feature is designed to be used in conjunction with ProGet as a proxy to the public repositories. It's not a "stand-alone" tool, so it won't work well if packages aren't in ProGet.
The reason is, if the package metadata isn't in ProGet, it has to be searched for on a remote server. In your sample (one build, two packages), you're right.. it's just a few seconds to search that data on nuget.org. But in production, users have 1000's of active builds each with 1000's of packages... and that *currently * takes about an hour to run an analysis.
That is how every other SCA systems works, that does not have a built-in package server.
Right now we are using DepTrack behind ProGet as a caching proxy. If DepTrack wants to analyze any package it will just pull the information from ProGet, if that package is already cached, great. If that package is not cached ProGet will download it and it will be cached from here on out, zero manual intervention required.
This very same scenario will not work in ProGet without manual intervention by either adding packages on some exclusion list or downloading them manually to populate the cache.
This limitation will always put ProGet SCA in a disadvantage when being compared to other systems.
Adding 100k's of network requests to connectors to constantly query nuget.org/npmjs.org for server metadata would add hours to that time, triggers api rate limits, and causes lots of performance headaches. Plus, this "leaks" a lot of data about package usage, which is an added security concern. This is a major issue with tools like DependencyTrack - they're basically impossible to scale like ProGet.
I agree, this is not how things should be set up. If someone decides to run a setup like this, they are not doing a good job.
ProGet should always be in the middle as a caching proxy and the cache download should only be there to fill the gaps for packages that for whatever reason are not available yet.